■ 11_04. コンピューターで扱う文字 ■
■ バイナリデータ
コンピュータは理論的に二進法で動いており、二進法をバイナリ(binary)と言うので、
コンピュータが扱うデータを、バイナリ・データと言います。
バイナリ・データの中でも、中身が文字だけのものを、特にテキスト・データと呼びます。
テキストは「単なる文字=誰でも見ればわかる文字」、バイナリは、そうでないものです。
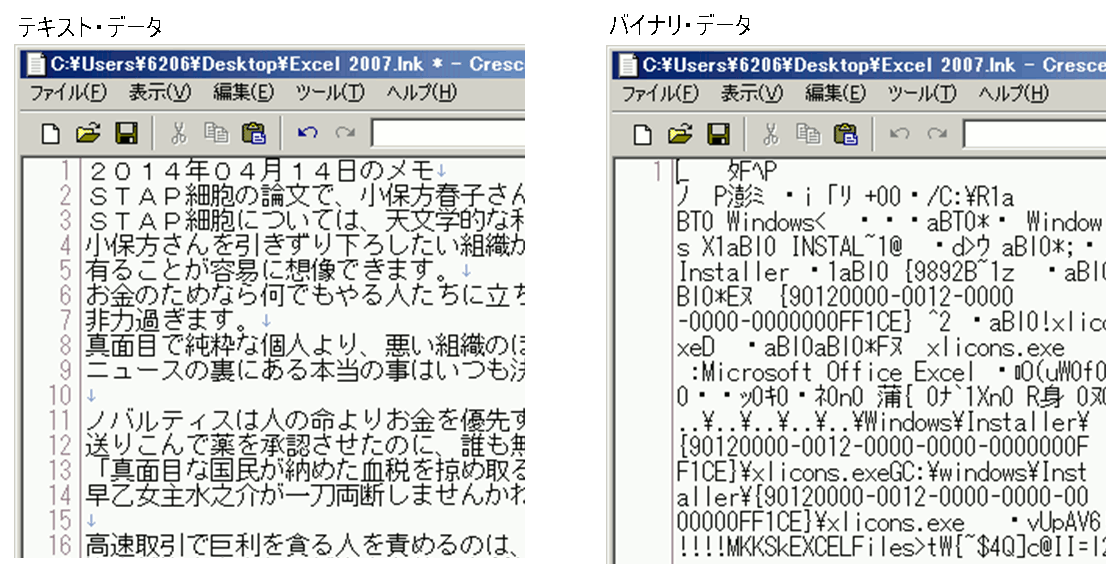
下図はテキスト・エディタで、テキスト・データ と バイナリ・データを見た例です。
左のテキスト・データはちゃんと読めますが、右のバイナリ・データは チンプンカンプンです。
WordやExcelは、文字を扱うだけなく、図表や画像まで扱います。
文字の拡大・縮小、太字、色付けなど、いろんな文字操作もできます。
書式情報などが付加されるので、単なるテキストではなく、バイナリ・データとして扱います。
テキスト・データを保存したものがテキスト・ファイル、
バイナリ・データを保存したものがバイナリ・ファイルです。
ウェブ・ページの中身 HTMLファイルは、テキストのみで書かれたテキスト・ファイルの一種です。
バイナリ・ファイルには画像ファイルや音声ファイル、圧縮されたファイルなどがあります。
プログラマは、ソース・コードをテキスト、コンパイルされた実行ファイルをバイナリと分類します。
商用ソフトは無断の改変を防ぐためソース・コードを公開せず、実行ファイルのみ販売されますが、
オープン・ソフト は、世界中のプログラマがソフトウェアを自由に利用・改良・改善できるように、
設計仕様書も、ソース・コードも、無償で公開しています。
因みに、バイナリ・エディタは、バイナリ・ファイルを1バイト単位で表示・編集するツールです。
■ テキストとエディタ
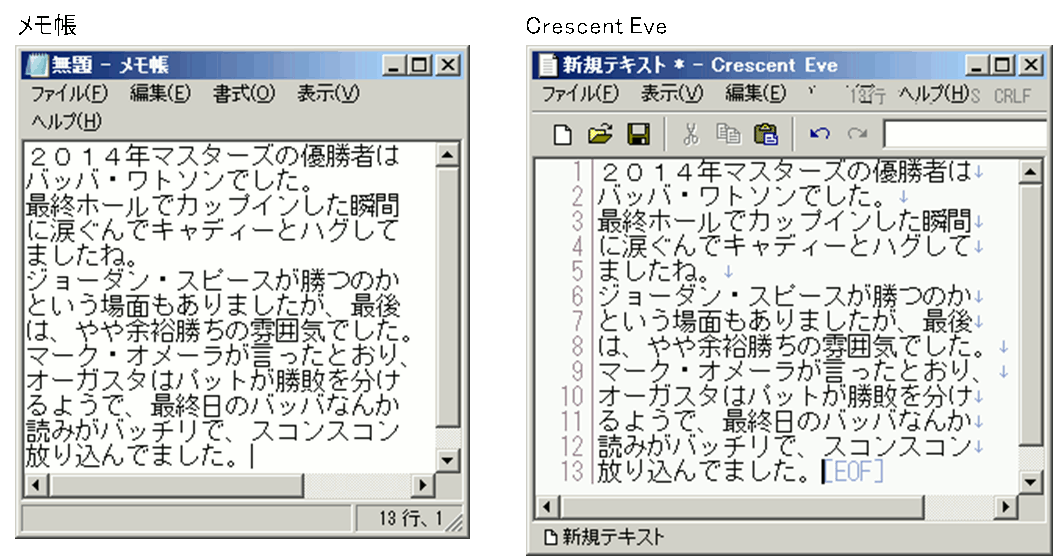
テキストを編集するツールがテキスト・エディタですが、普通は単にエディタと言います。
エディタは、プログラマがソース・プログラムを書く道具ですが、簡単な文書作成にも使えます。
Windowsに付属する「メモ帳」の他に、Crescent Eveなど様々なテキスト・エディタがあります。
■ 拡張子の役割
コンピュータにとっては、一般のデータも実行プログラムも、二進数が並んだファイルに過ぎません。

良い悪いは別に、人を外見で判断する様に、コンピュータも拡張子でデータの中身を判断します。
ファイル名の拡張子(かくちょうし)によって、データをどのように扱うかを決めます。
テキスト、ワープロ文書、画像などのデータは、.txt .doc .jpg などの拡張子で分類します。
実行プログラムの拡張子は .exe です。

■ 拡張子によるファイルの分類
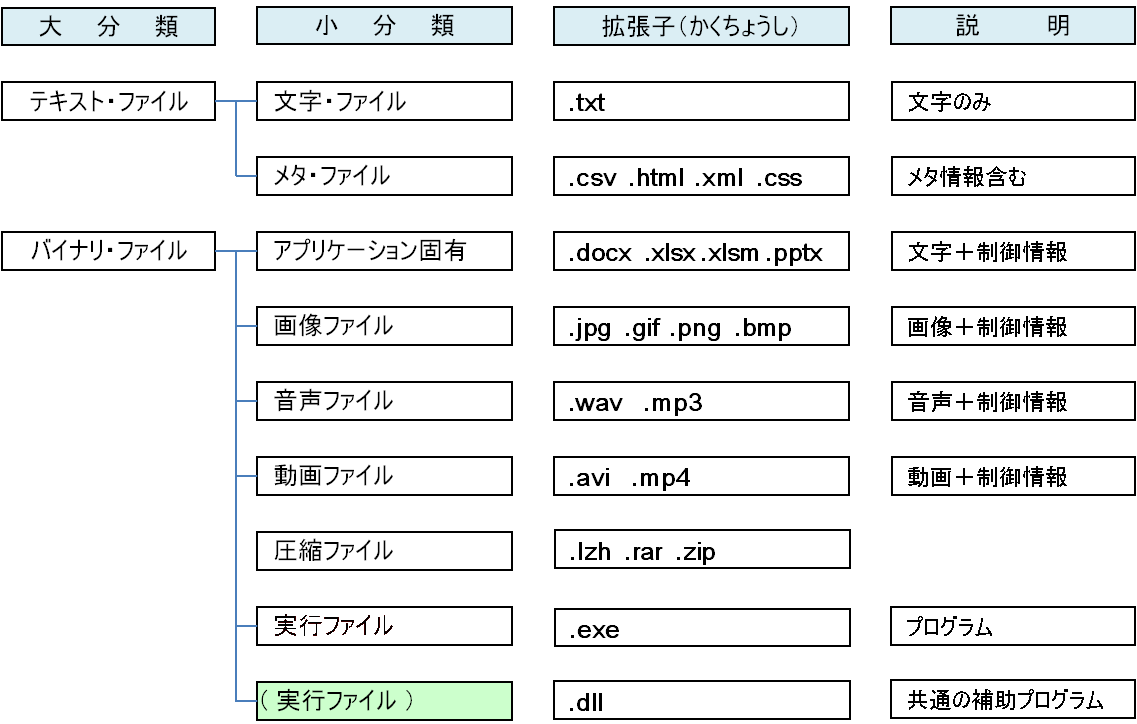
拡張子辞典が在るくらい、たくさんの拡張子がありますが、主なものをまとめました。
■ 文字コード
コンピュータ上で文字を扱うときは、「文字」と一対一に対応する二進数のコードを用います。
これが 文字コード で、その代表的なものが ASCII (アスキー)コードです。
ASCIIコードは、7桁の2進数(10進数では0~127)(16進数では0x00~0x7f)で表します。
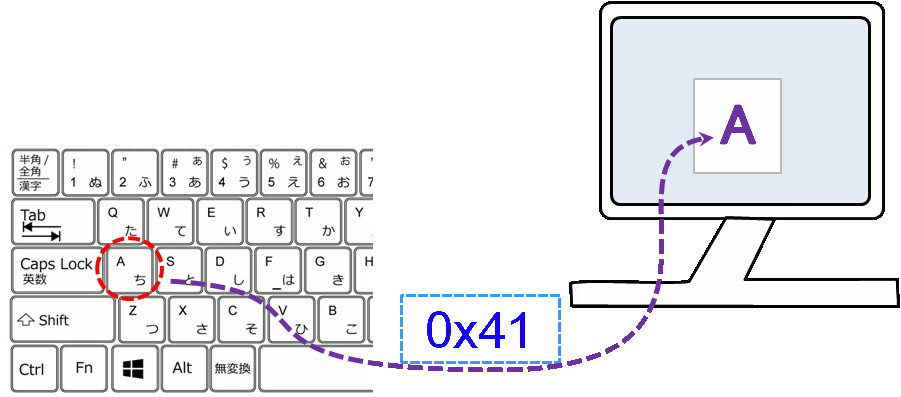
キーボードから半角大文字「A」を入力すると、ディスプレイに「A」と表示されますが、、、
コンピュータが「A」という文字を認識して、「A」がコンピュータの中を巡るわけではありません。
「A」のASCIIコードは 41 (16進数なので 0x41 と表現します)なので、
キーボードから「A」と入力すると
コンピュータは 0x41 を持ち回り ディスプレイに「A」を表示します。
コンピュータがアメリカで発明・発展したこともあり、ASCIIコードは英語圏を前提に作られました。
グローバルな今の世界では、なおさらASCIIコード抜きにコンピュータの利用はありえません。
各国の文字コードはASCIIコードと併用せざるを得ないのです。
■ 制御コード
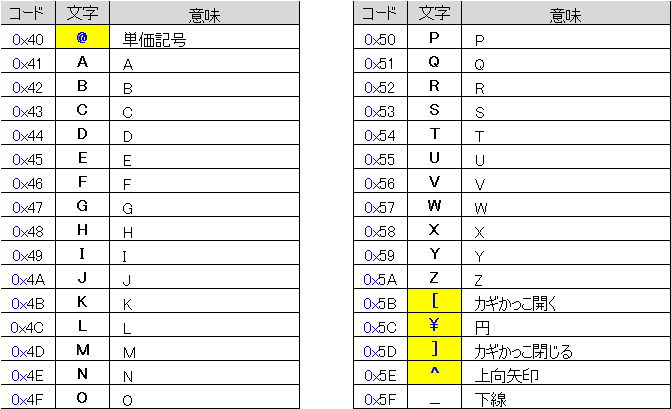
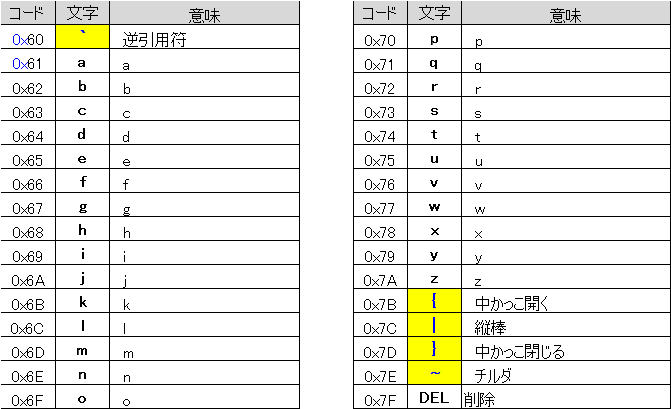
下図は制御コードも含めたASCIIコード表です。
0x00 や 0x7Fの 0x というのは、16進コードの意味です。
16進数なので、10=A、11=B、12=D、14=E、15=F で表し、16になると桁上がりします。
ASCIIができた頃、通信性能は悪く HDD容量も小さかったので、少しでもムダな情報を省くために、
多くの制御コードと、7ビットという中途半端なビット数の文字コード体系ができました。
ASCIIコード表
7桁の2進数(10進数では0~127)で表せる128種類のコードです。
0~127を16進数で表現すると、0x00~0x7Fになるので、
2ケタ目を列、1ケタ目を行に置き換えて表にしています。
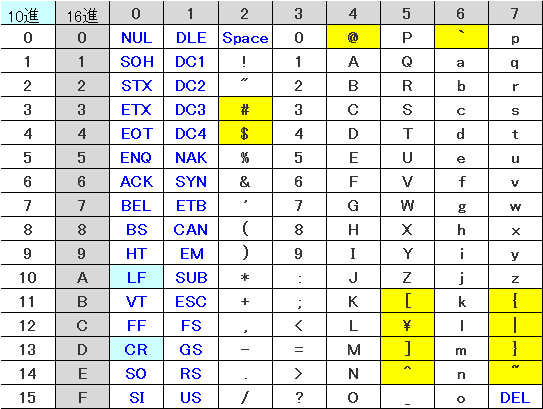
上表の 0x00(NUL)~0x20(Space) と 0x7F(DEL) が制御コードです。
制御コードは 元々通信制御のためのコードですが、近年は、その多くが使われなくなりました。
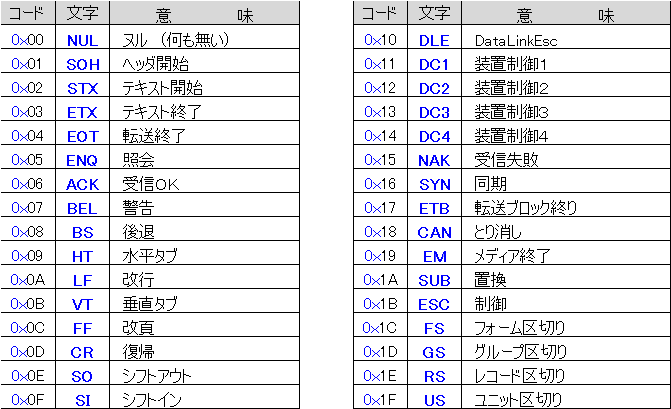
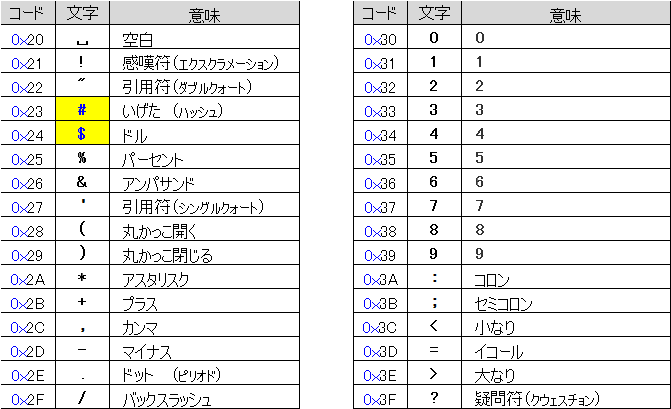
バックスラッシュに該当する日本語文字は無く、0x2f は フォントにより見え方が変わります。
S明朝やゴシックなどの日本語フォントでは¥ arial など欧文フォントでは\が表示されます。
■ 改行コード
「改行」をどの制御コードに対応させるかは、データ変換時に、重要なことです。
「改行」を表すコードは、
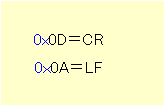
と、2つあります。
タイプライターを入力に使っていた頃、
CR(Carriage Return) は、印字ヘッドを左端(行頭)に移すこと、
LF(Line Feed)は、1行送る(印字ヘッドを次の行に移す)こと、
を意味していました。

残念なことに「改行」は現在広く用いられているコンピュータで一致した使い方になっていません。
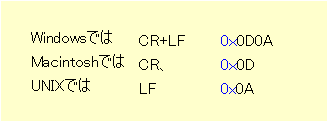
が改行を表現する決まりです。
これら異なるOSの機器どうしでデータ交換するときは、改行コードを変換する必要があります。
■ ISO 646
ASCIIコードが 7ビットでは、ヨーロッパ諸国や日本などで不便なため、ISO 646ができました。
ISO 646では、7ビットASCIIを基本に、12箇所は各国で文字コードの入れ替えを許可しています。

■ ISO 8859
ISO 646では、12文字しか入れられない上、ASCII との互換性が失われる問題がありました。
コンピュータの性能が飛躍的に高まり、ディスク容量も大きくなりました。
このような背景から、ISOでは文字コードを7ビットから8ビットに拡大し ISO 8859 ができました。
8ビット前半のコード領域は、7ビットASCIIから拡張されたISO 646のままとし、
8ビットの後半のコード領域128文字(0xA0~0xFF)に各国固有の文字や記号を割り当てます。
欧州全域を視野に入れたものでしたが不幸にも使われる文字数を低く見積もってしまいました。
結局 128 文字ではヨーロッパの全文字を網羅できず、複数の ISO-8859 が生まれました。
ISO 8859-1 ~ ISO 8859-10 まであり、ヨーロッパは文字化けが深刻らしいです。
ISO 8859-1(Latin-1)は主要な西欧言語に対応するラテン文字セットで、主流になっています。
英語・ドイツ語・フランス語など西欧の主要言語をカバーし各国文字を混在させた文章もOKです。
■ エスケープ・シーケンス
エスケープ・シーケンスはテキスト文字列に埋め込み、属性の切り替えに使われる文字の並びです。
ASCIIコードの 0x1B ESC(制御) で始まるためエスケープ・シーケンスと呼ばれます。
JISコード(JIS X 0202)では、エスケープ・シーケンスで、以降に続く文字を切り替えます。
例えば、0x1B2842 ESC ( B で、ASCII 文字に切り替えることになります。
文の始まりはASCIIと仮定します。
具体的には、次の4つの「文字セット」をエスケープシーケンスで切り替えています。

次の16進数の文字列は、

以下のような文字コードがつながったもので、
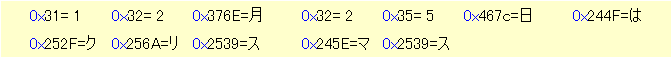
表示すると、こうなります。

WordやExcelで文字入力している時、コンピュータ内部では二進数(表現は16進数)の文字コードや
エスケープ・シーケンスが、規則に従って並んでいるわけです。
■ ユニ・コード (Unicode)
Unicodeは世界中の文字をまとめて表現するために規格された文字コードです。
Unicodeの文字コード・セットを、UCS( Universal Coded character Set )と言います。
■unicode抜粋
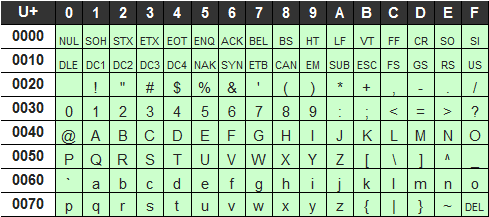

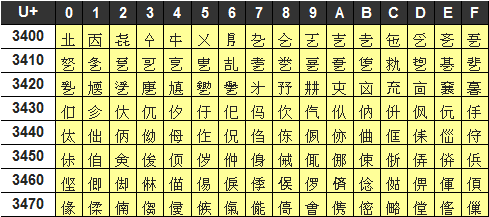
Unicodeには、欧米、アジア、中東、アフリカなど、世界中の文字が入っています。
単純な文字だけでなく、欧州のアクセント記号や日本の濁点、半濁点付きなども入ってます。
世界中の文字が使えますが 日本のアプリでヨーロッパのUnicodeをうまく表示できないことがあり、
逆に、ヨーロッパのアプリで日本語がうまく表示できないこともあります。
実際、アプリケーションがUnicodeをどこまでカバーするかは、そのアプリを作る人次第です。
アプリが正しく表示出来ない文字が入力されると、想定外なので、何が起こるか分りません。
これはUnicodeに限った話では有りません。
アプリにとって想定外の文字コードを大量に入力すると、異常な表示、異常な動作につながります。
めったに使わないUnicode文字を入れると、LINEが遅くなったり落ちる、という現象があります。
以下は(想定外文字コードをウィルスと感じた)高校生の、LINE被害メッセージの実物です

インターネットは、全くの他人とも、簡単に連絡を取り合えるので、基本は「性善説」ですが、、、
使う人が爆発的に増えて、誰が何を送ってくるか、わからなくなりました、、、
■ Unicodeのエンコード(文字符号化)方式
Unicodeの文字セットは、UCS 一種類だけでした、、、
これに対し、Unicodeのエンコード方式は、たくさんあります。
Unicodeの文字セットをコンピューターに格納する方式が、複数あるのです。
例えばメモ帳で、名前を付けて保存する場合のエンコードと文字コードは、、、、

UTFは、Unicode Transformation Format (Unicode変換形式) の略です。
unicodeの用語としては8ビットを1オクテット(Octet)と言います。
■ UTF-16(ビッグ・エンディアン) Big Endian
文字データの先頭に 0xFEFF(2オクテット)のBOM(バイト順マーク)を書き込みます。
0xFEFF=「幅ゼロの改行なしの空白」(Zero Width Non Breaking Space)ZWNBSです。
ZWNBSを先頭に入れる理由は、Unicodeのエンコード方式がいろいろあるので、
読み込むプログラムに、文字データをどの方式でエンコードしたか伝えるためです。
U+0000~U+FFFFまでのUnicodeスカラー値はそのままの16進数16ビットになりますが、
U+10000以降の文字は、16進数32ビット、つまり16ビット文字2つになります。
これを サロゲート・ペア といいます。
BOM = Byte Order Mark
スカラー = 梯子 = スケールと同義
サロゲート= 分身 = ブルースウィルス主演のSF映画がありました
つまり、UTF-16(ビッグ・エンディアン)は、
16ビット文字1つまたは2つの可変長コードになります。
U+0000~U+FFFF は文字セットと文字符号化方式の区別をせずに済みますが、
U+10000~は、unicodeスカラー値とUTF-16文字コードがかけ離れた値になります。
サロゲート・ペアは、サポートしているアプリとしていないアプリがあり、
サポートしていないアプリでサロゲート・ペアを表示させると、何がおこるかわかりません。
■ UTF-16(リトル・エンディアン) Little Endian
文字データの先頭に 0xFFFE (2オクテット)のBOM(バイト順マーク)を書き込みます。
リトル・エンディアンはビッグ・エンディアンを16ビット単位でひっくり返したものです。
Unicodeでは、U+FFFEという文字は絶対に定義されないことになっています。
先頭のBOMが U+FEFF → ビッグ・エンディアン、U+FFFE → リトル・エンディアン と分かります。
UTF-16に ビッグ・エンディアン と リトル・エンディアン の2種類があるのは、
パソコンのCPUが16ビットだった頃、インテルとモトローラでチップ内の演算方式が違ったためとか。
ガリヴァー旅行記で
「ゆで卵を大きな端(big end)から食べるのと小さい端(little end)から食べるのと
どっちが食べやすいか」という議論で戦争になった部族になぞらえ、
ビッグ・エンディアン、リトル・エンディアンと呼ばれているらしいです。
■ UTF-8
文字データの先頭に 0xEFBBBF(3オクテット)のBOM(バイト順マーク)を書き込みます。
ISO 8859-1の範囲は(欧米では)、ISO 8859-1と完全互換の8ビット=1オクテットです。
半角カナは3オクテットになります。
漢字の外字は4オクテットになります。
このように、UTF-8は1オクテット以上の可変長文字です。
規格上は6オクテットまで存在しますが、現在4オクテットまでしか使われていません。
■ 文字コードの現物
文字コード表はネット上に公開されています。
文字コードを覚える必要は全くありませんが、どんな構成か、一度は確かめておいて下さい。
(例)日本語JISコード http://charset.7jp.net/jis.html